Plug-and-Play Self-Supervised Temporal Consistency Refinement for Monocular Depth Estimation in Video
Abstract
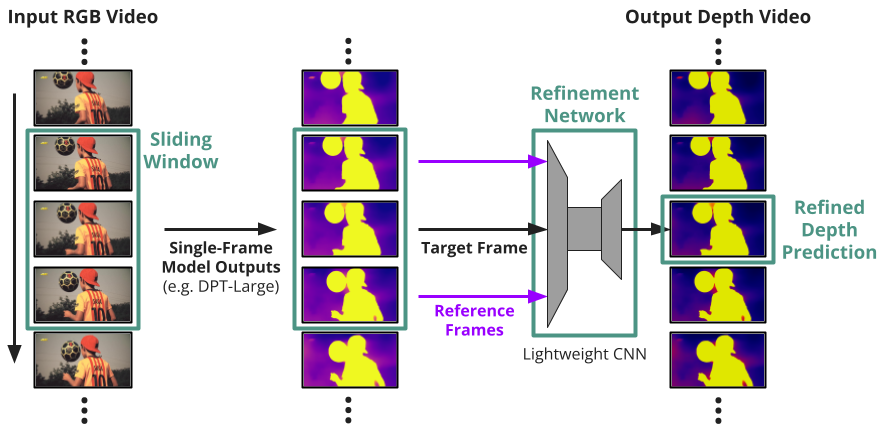
A key challenge in monocular depth estimation in video is ensuring cross-frame consistency in predictions. Current methods address this difficulty by incorporating temporal information into their models. However, many approaches either require significant modification to the original depth estimation pipeline, making them inflexible, or use bulky components such as attention mechanisms or diffusion, making training resource-intensive and inference computationally heavy. To address these shortcomings, we propose a self-supervised refinement model that acts as a plug-in to existing state-of-the-art single-image monocular depth estimation models. We implement our method as a lightweight convolutional neural network that takes a sliding window of depth prediction frames to refine the central frame. Through a self-supervised training process, our model learns to enforce temporal and visual consistency with smooth and stable predictions by employing bidirectional flow warping and regularization. We evaluate our method against benchmark video monocular depth estimation models in terms of spatial accuracy and temporal consistency metrics. Experimental results show that our design consistently improves single-frame depth predictions and is comparable to the current state-of-the-art models.